Federated Learning
Federated learning is a machine learning technique that trains an algorithm across multiple edge devices or servers holding local data samples, without exchanging them.
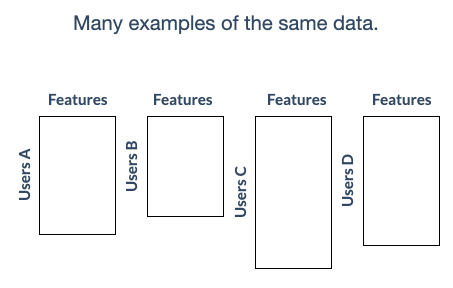
This approach stands in contrast to traditional centralized machine learning techniques where all the local datasets are uploaded to one server, as well as to more classical decentralized approaches which often assume that local data samples are identically distributed.
Federated learning enables multiple actors to build a common, robust machine learning model without sharing data, thus allowing to address critical issues such as data privacy, data security, data access rights and access to heterogeneous data.
We support Federated Averaging and Split Learning implementations.
How does Split Learning work?
Split learning attains high resource efficiency for distributed deep learning in comparison to Federated Averaging by splitting the models architecture across distributed entities. It only communicates activations and gradients just from the split layer unlike other popular methods that share weights/gradients from all the layers. Split learning requires no raw data sharing; either of labels or features.
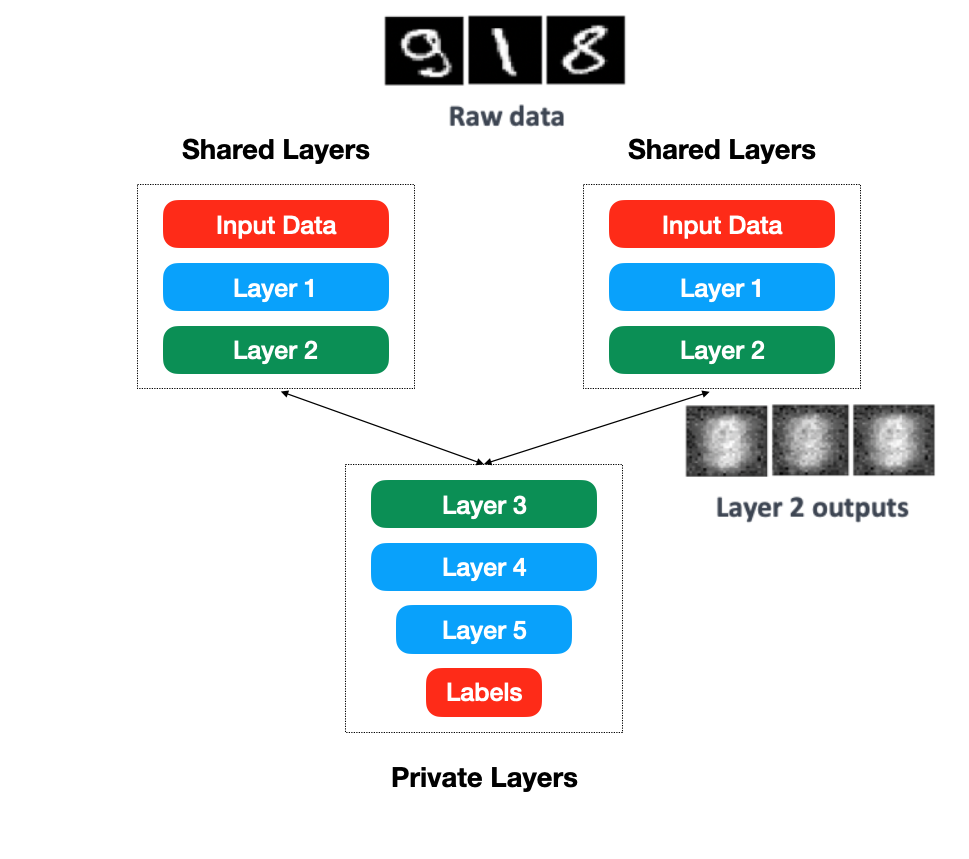
Learn more on the Split Learning page at the MIT Media Lab’s website.
Federated Averaging, how it works?
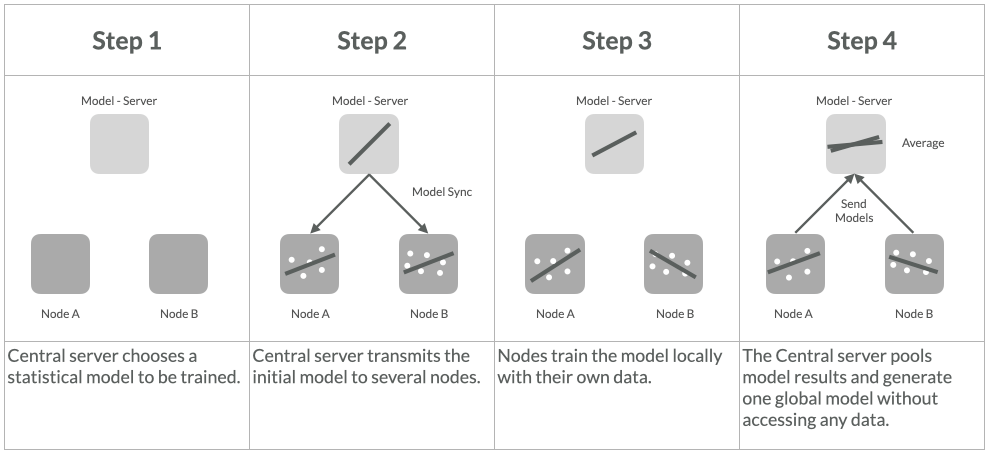
Check out our first implementation at coMind, it was the first open source library available. Currently the implementation in Acuratio Platform is more advanced and has better performance. It also supports many more functionalities like secure aggregation, differential privacy and compression mechanisms like random rotation matrices or sparse ternary compression.
Find out more at hello@acuratio.com.